为什么需要空间索引
在时空数据中,单个对象不仅仅包含属性信息,还包含了空间信息 和 时间信息,传统的关系型数据库提供的 R+ 树的索引,一般是针对字段值进行索引的,比如说常见的,根据对象的 时间信息进行索引、或者是根据字段的 Id 进行索引。
但是在一些 涉及到空间操作的情况下,传统索引基本上是需要走全表扫描的,类似与查找某个位置周围 10 km 的对象,这种查询,传统的索引只能是全表扫描,计算每个对象和特定位置的距离,最后输出结果,本质上来说,这种查询扫描了大量的无关数据,不利于高并发的数据查询响应。
空间索引的常见类型
空间索引,从字面意思上来讲,就是基于空间位置,过滤掉一大批无关数据,实现数据查询的加速。目前常见的空间索引包含以下几种
- 空间网格索引
- 四叉树索引
- GeoHash 索引
- R 树 索引
- 空间填充曲线
网格索引
将整个数据范围,按照一定的长宽,划分成均匀的网格。生成索引的过程,就是遍历所有的空间对象,查找到每个空间对象应该所属的网格,如果一个对象是跨多个网格的,这个对象就应该存在于多个网格内(如下图)
在进行数据查询时,需要首先找到需要查询的网格。以缓冲区查询为例,找到 A 点 周围 10km 的要素。
(1)首先查询到 A 点 周围 10 km 的网格 (2)查询 网格内的对象 (3)具体判断 对象和 A 点的实际距离
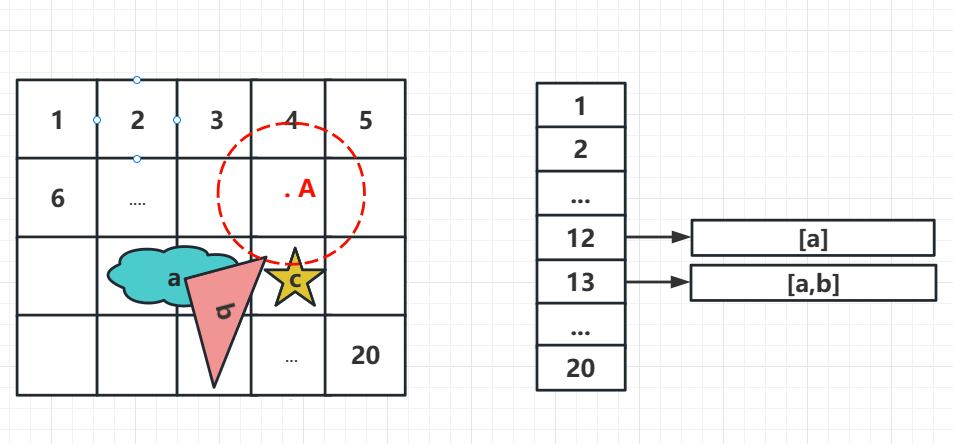
总体流程如下:
- 确定网格大小,拆分查询区域
- 遍历对象,分配对象到特定的网格
- 查询对象时:首先查询满足条件的网格,通过网格来过滤一部分对象
- 增加对象时:添加 对象的到特定的网格内
- 删除对象时:删掉网格中对目标的索引
优缺点
1
网格索引,优点在于构建和网格的更新都十分遍历,维护的成本较低。缺点:一大部分的网格是没有使用的,同时网格的大小,预先不好设置,太小和太大都会造成问题。
四叉树索引
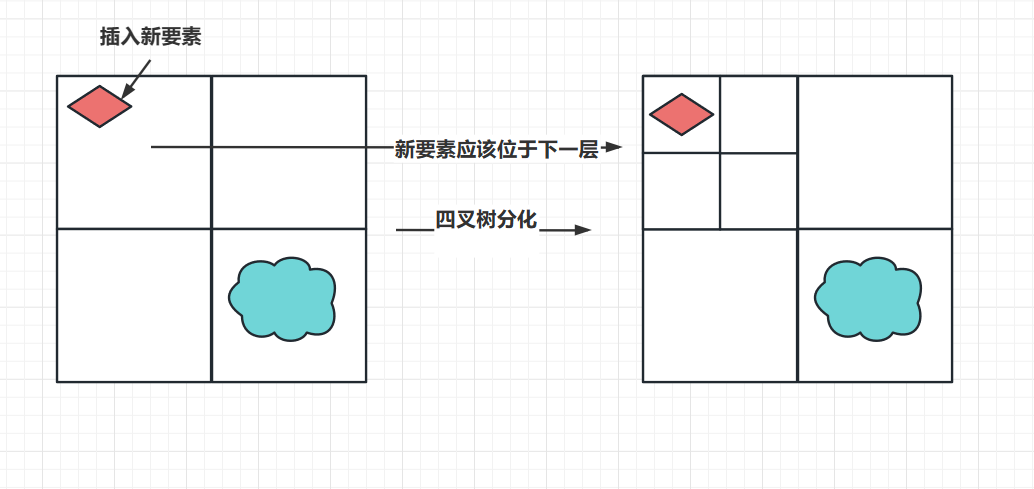
四叉树索引,简单来说,就是将区域按照中心点,使用水平、竖直划分,拆分为四个相同的部分,记录每个部分内的对象。
如果划分后,新插入的对象没有 跨越上层的多个部分时,就需要对原始数据进行进一步划分,具体的划分层数,人为的限制,防止拆分程度过深,从而降低查询的效率。具体的划分层级的确定,取决研究区域对象的数量和平均大小
四叉树索引的存储模式和B+树,有一定程度上的类似,按照树的方式来组织,对于非叶节点,每一个节点有四个子节点。所有的对象,只存在于叶节点上,中间结点,只保存一个四叉树对应的索引信息。
但是 四叉树不是平衡树,如果数据在空间分布上不均匀,就很容易造成树的退化,从而降低查询效率,但是在数据分布均匀时,四叉树有非常高的查询和编辑效率。
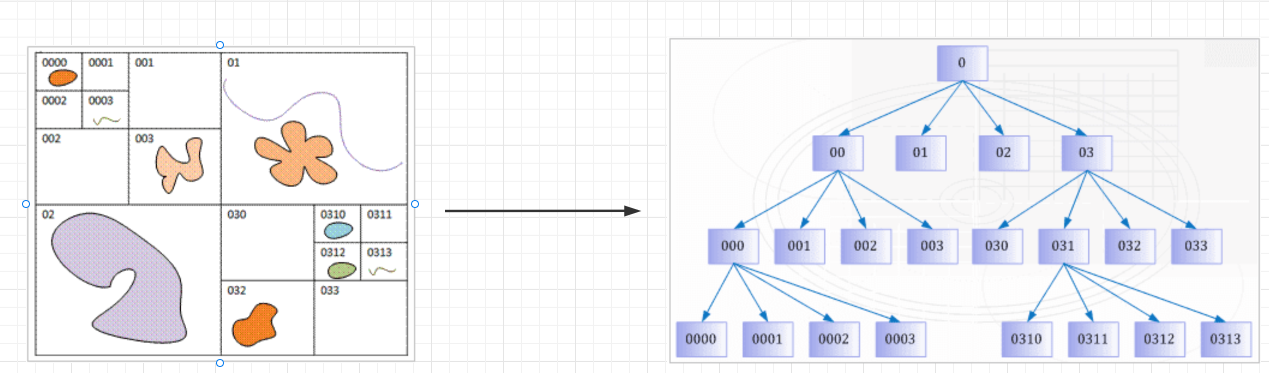
优缺点
- 优点:四叉树组织形式下,空余的结点数量相对于网格索引来说,查询效率更高
- 缺点:四叉树存在数据冗余的问题,一个较大的元素可能跨越多个索引区域,例如上图的
02内的元素,如果要继续拆分02,那么该元素就会存在于多个子节点中,产生数据冗余,降低查询的效率。
扩展 四叉树索引存在非常多的改进种类,例如 点四叉树、线性可排序四叉树,PR四叉树,同时四叉树的结点分裂也有不同的方式,比如说上文提到的,按照对象的分布来拆分,也有按照结点内元素的个数来划分(比如说超过了一定的规模,一个结点内有四个元素时,就可以拆分结点了)
GeoHash
GeoHash 算法,将经纬度数据联合编码为一个字符串,并且按照字符串从头到尾的相似程度来进行索引。不同的字符串位数,也代表了不同层级的地理网格。
从具体的数据划分角度来说,GeoHash 是一种分层的,网格状的数据结构,将全球的经度 $[-180,180]$ 和纬度 $[-90,90]$ 进行划分,形成一个按照层级来展开的网格索引。每一个网格有独立的、不重复的、前缀相同的编码,如下图。 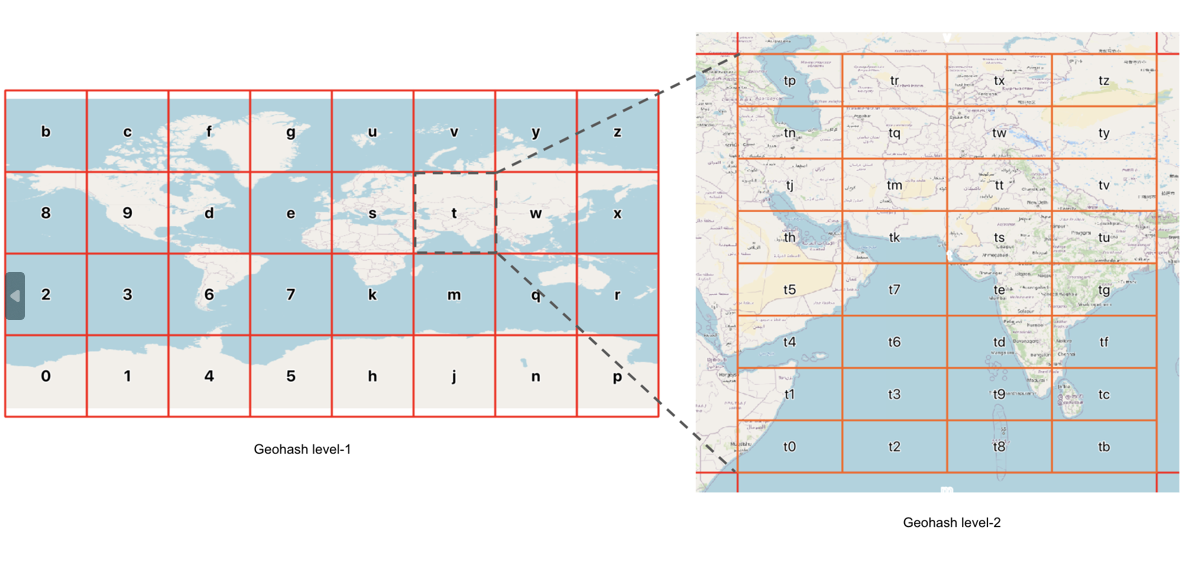
具体的编码过程 以武昌火车站为例 114.323865,30.534349,首先需要将经纬度转换为二进制编码 114.323865 按照二分法迭代划分,得到的二进制串为 11101001010
| bit | min | mid | max |
|---|---|---|---|
| 1 | -180 | 0 | 180 |
| 1 | 0 | 90 | 180 |
| 1 | 90 | 135 | 180 |
| 0 | 90 | 112.5 | 135 |
| 1 | 112.5 | 123.75 | 135 |
| 0 | 112.5 | 118.125 | 123.75 |
| 0 | 112.5 | 115.3125 | 118.125 |
| 1 | 112.5 | 113.90625 | 115.3125 |
| 0 | 113.90625 | 114.609375 | 115.3125 |
| 1 | 113.90625 | 114.2578125 | 114.609375 |
| 0 | 114.2578125 | 114.4335938 | 114.609375 |
纬度 30.534349 同样进行拆分 $[-90,90]$ 进行编码,10101011011
| bit | min | mid | max |
|---|---|---|---|
| 1 | -90 | 0 | 90 |
| 0 | 0 | 45 | 90 |
| 1 | 0 | 22.5 | 45 |
| 0 | 22.5 | 33.75 | 45 |
| 1 | 22.5 | 28.125 | 33.75 |
| 0 | 28.125 | 30.9375 | 33.75 |
| 1 | 28.125 | 29.53125 | 30.9375 |
| 1 | 29.53125 | 30.234375 | 30.9375 |
| 0 | 30.234375 | 30.5859375 | 30.9375 |
| 1 | 30.234375 | 30.41015623 | 30.5859375 |
| 1 | 30.41015623 | 30.498046875 | 30.5859375 |
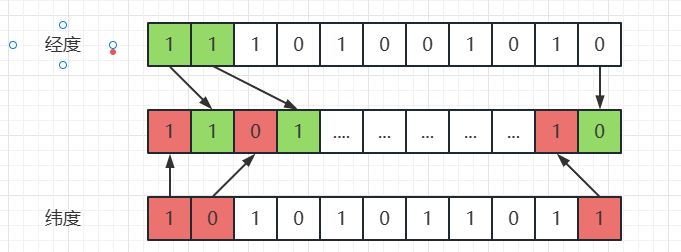
将经纬度编码后得到的二进制串,进行交叉组合,一位纬度、一位经度进行组合,得到一个编码后的二进制串
1101110011001011001110![image.png]()
- 最后,将二进制串,按照
Base32的编码方式,编码为字符串,得到结果wt3m9w85,即原始的坐标经过编码后的字符串。 - 因为交替编码,可以使得经纬度相近的元素,编码得到的结果中,相同的前缀越长,因此 GeoHash 也常常用于空间聚类
理论上来讲,GeoHash 表达的是地球表面上的一个矩形范围,而不是一个点,但是当矩形范围足够小时,就可以使用 这个矩形范围来表达点了。
GeoHash 的精度 和 字符串编码后的长度如下,字符串的长度越长,表达的矩形范围就越小,当字符串达到 8位时,矩形的范围为19m
| geohash length | lat bits | lng bits | lat error | lng error | km error |
|---|---|---|---|---|---|
| 1 | 2 | 3 | ±23 | ±23 | ±2,500 km (1,600 mi) |
| 2 | 5 | 5 | ±2.8 | ±5.6 | ±630 km (390 mi) |
| 3 | 7 | 8 | ±0.70 | ±0.70 | ±78 km (48 mi) |
| 4 | 10 | 10 | ±0.087 | ±0.18 | ±20 km (12 mi) |
| 5 | 12 | 13 | ±0.022 | ±0.022 | ±2.4 km (1.5 mi; 2,400 m) |
| 6 | 15 | 15 | ±0.0027 | ±0.0055 | ±0.61 km (0.38 mi; 610 m) |
| 7 | 17 | 18 | ±0.00068 | ±0.00068 | ±0.076 km (0.047 mi; 76 m) |
| 8 | 20 | 20 | ±0.000085 | ±0.00017 | ±0.019 km (0.012 mi; 19 m) |
参考文章